Architecture Overview
SGJM Team is implementing the Ultimo (Advanced) architecture specification, featuring microservices backend, headless UI frontend, and event-driven communication.Target Architecture
Frontend
Headless UI Architecture - React with TanStack Query & Router - Zustand
for state management - Shadcn/ui with Tailwind CSS - Reusable headless
components
Backend
Microservices Architecture - Spring Boot services - Bounded context per
service - Database per service - Database sharding by Country
Messaging
Kafka Message Broker - Real-time event streaming - Cross-subsystem
communication - Pub/sub for notifications
Deployment
Containerized Infrastructure - Dockerized services - Service Discovery -
API Gateway - Multi-host deployment
Architecture Levels
Simplex (Basic) - N-Tier Architecture
Foundation layer-based architecture separating concerns
Additional Features (A.1.3):
- Cookie Configuration
- Security Filters
- Token Generators
- Exception Handlers
Medium - Modular Monolith Architecture
Module Structure (A.2.1, A.2.2):- External APIs
- Internal APIs
Public Services exposed via interfaces - Available to other modules -
Defined contracts - Versioned endpoints
- External DTOs: Shared across modules
- Internal DTOs: Module-private only
- Minimize data exposure in responses
Ultimo - Microservices Architecture
Advanced Distributed Architecture
Fully distributed system with independent services, databases, and deployment
Authentication Service
Authentication Service
Bounded Context: User authentication and authorization
- Company registration
- Login/Logout
- Token management (JWE)
- SSO integration
- Token revocation (Redis)
Profile Service
Profile Service
Bounded Context: Company profile management
- Profile CRUD operations
- Media uploads
- Shard management
Job Service
Job Service
Bounded Context: Job post management
- Job CRUD operations
- Skills tagging
- Application tracking
- Kafka publishing
Search Service
Search Service
Bounded Context: Applicant search
- Full-text search
- Skill filtering
- Shard-aware queries
- Lazy loading
Subscription Service
Subscription Service
Bounded Context: Premium subscriptions
- Subscription management
- Search profile configuration
- Match evaluation
- Kafka consumption
Payment Service
Payment Service
Bounded Context: Payment processing
- Stripe/PayPal integration
- Transaction recording
- Webhook handling
Notification Service
Notification Service
Bounded Context: Real-time notifications
- WebSocket connections
- Kafka consumption
- Email notifications
Country used as sharding key for optimal query routing
Headless Component Pattern
Headless Component Pattern
Separate logic from presentation for maximum reusabilityExample: Data Table ComponentShared Templates:
- Tables (job posts, applications, applicants)
- Forms (login, registration, profile edit)
- Modals (confirm delete, view details)
- Cards (job card, applicant card, company card)
Frontend Component Diagrams
View detailed C4 component diagrams for all 7 frontend feature modules, including Signup, Login, Dashboard, Profile, Subscription, Job Post, and Applicant Search.
System Context Diagram
The C4 System Context diagram provides a high-level view of the Job Manager system and its interactions with external actors and systems.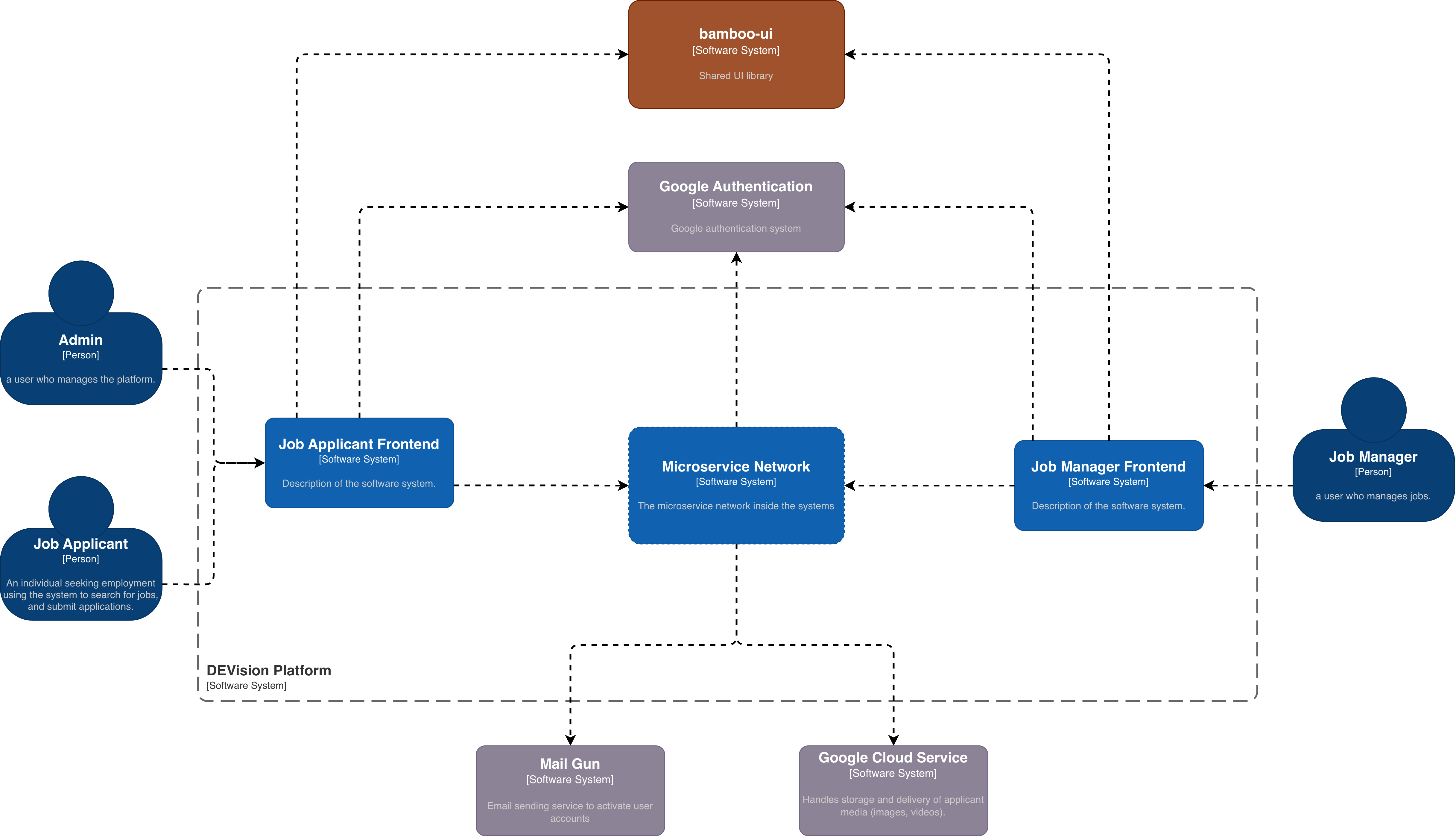
Context Overview
Primary Actors
- Company Recruiters - Create and manage job posts
- Job Applicants - Search and apply for jobs
- System Administrators - Manage platform operations
External Systems
- Job Applicant (JA) System - Candidate management subsystem
- Payment Gateway - Stripe for premium subscriptions
- Identity Providers - Google OAuth for SSO
- Email Service - Mailgun for notifications
Backend Container Diagram
The Job Manager backend follows a microservices architecture with clear separation of concerns. Each service has its own bounded context, database, and communicates via REST APIs and Kafka events.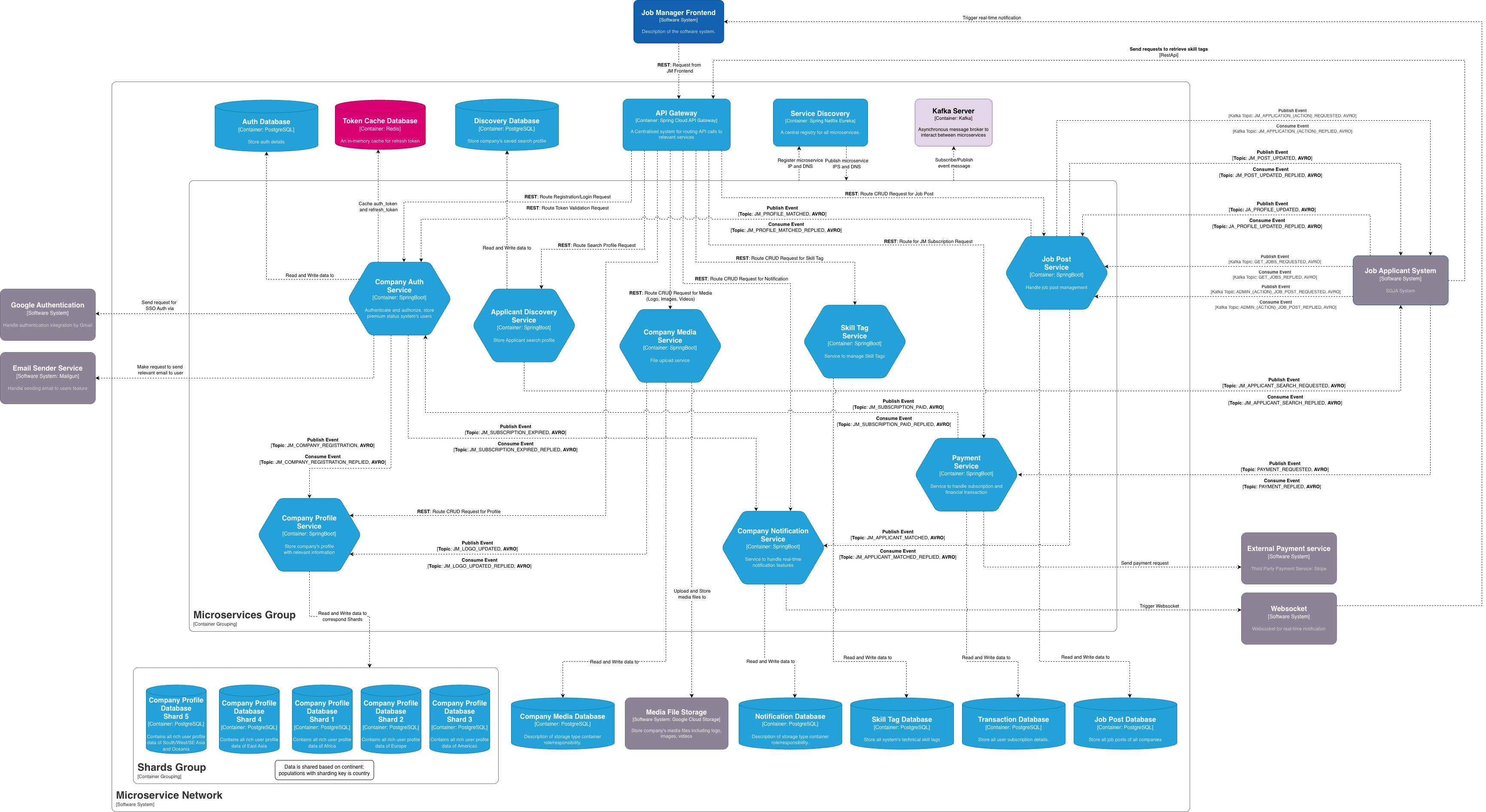
Container Overview
Infrastructure Layer
- API Gateway (Spring Cloud Gateway)
- Service Discovery (Eureka)
- Kafka Cluster for event streaming
- Redis for token caching
Core Microservices
- Company Auth Service
- Company Profile Service
- Job Post Service
- Payment Service
Supporting Services
- Company Media Service
- Notification Service
- Applicant Discovery Service
- Skill Tag Service
External Systems
- Job Applicant (JA) Backend
- External Payment Service (Stripe)
- Google Authentication
- Email Service (Mailgun)
- Media File Storage (S3/GCS)
Container Descriptions
API Gateway & Service Discovery
API Gateway & Service Discovery
The API Gateway acts as the centralized entry point for the entire JM backend. Its responsibility is to accept incoming REST requests over HTTPS from the frontend system and route them to the appropriate microservices. It works in conjunction with Service Discovery (Eureka) to dynamically resolve the network locations of backend instances, ensuring that external clients interact with a stable interface regardless of internal infrastructure changes.
Company Authentication Service
Company Authentication Service
Responsible for identity management and orchestration of company registration workflows. Upon receiving login requests via REST, it generates JWE tokens and interacts directly with the Token Cache (Redis) to store and validate access and refresh tokens. For new account creation, the service publishes an asynchronous event to the Company Profile Service to create the initial company record and waits for confirmation. It also manages subscription states by consuming payment confirmation events and integrates with external email services for subscription expiration alerts.Kafka Topics:
- Publishes:
JM_SUBSCRIPTION_EXPIRED,JM_COMPANY_REGISTRATION - Consumes:
JM_PROFILE_MATCHED,JM_SUBSCRIPTION_PAID
Company Profile Service
Company Profile Service
Manages persistence and retrieval of core company information and “Applicant Marker” statuses. To handle data on a global scale, it connects to a cluster of Company Profile database shards, distributing data storage geographically. This service operates asynchronously to maintain data consistency; it consumes registration events from Company Auth Service to create initial records and listens for media update events from Company Media Service to automatically refresh logo URLs.Database:
profile_db_shard_[1-5] (5 geographic shards)Kafka Topics:- Consumes:
JM_LOGO_UPDATED,JM_COMPANY_REGISTRATION
Job Post Service
Job Post Service
Acts as the central recruitment engine, handling the lifecycle of job advertisements and serving as the primary bridge to the JA Backend. When a manager views applications, this container sends an asynchronous retrieval request to the JA Backend and awaits a reply. Similarly, when application status changes, it synchronizes with the JA Backend. It also broadcasts real-time notification events to alert applicants when relevant job posts are created or updated.Kafka Topics:
- Publishes:
JM_PROFILE_MATCHED,JM_JOB_POST_UPDATED,JM_APPLICATION_{ACTION}_REQUESTED - Consumes:
JA_PROFILE_UPDATED,GET_JOBS_REQUESTED,ADMIN_{ACTION}_JOB_POST_REQUESTED
Company Media Service
Company Media Service
Handles upload and management of rich media assets (logos, images, videos). Instead of storing binaries internally, it interfaces directly with external media file storage (Google Cloud Storage) to upload files. Once a company’s logo is successfully uploaded, it publishes an event to Company Profile Service to update the profile record with the new public URL.Kafka Topics:
- Publishes:
JM_LOGO_UPDATED
Applicant Discovery Service
Applicant Discovery Service
Dedicated to processing search queries initiated by company managers. It accepts search filter parameters via REST and forwards queries to the JA Backend by publishing asynchronous search requests. It then waits for and consumes search results, aggregating data to return comprehensive result sets. Additionally, this service manages a dedicated Discovery Database to store and manage saved search profiles for premium users.Kafka Topics:
- Publishes:
JM_APPLICANT_SEARCH_REQUESTED
Payment Service
Payment Service
Isolates all financial transaction logic and acts as the secure interface for the External Payment Service (Stripe). It processes premium subscription requests and, upon successful transaction, publishes events to Company Authentication Service to upgrade account status. It also supports the JA Backend by consuming applicant-side payment requests and sending back transaction results.Kafka Topics:
- Publishes:
JM_SUBSCRIPTION_PAID - Consumes:
PAYMENT_REQUESTED
Notification Service
Notification Service
Aggregates system-wide events to generate real-time alerts for company managers. It monitors critical business events such as subscription expiration alerts from Company Auth Service. It also listens to applicant match events from Job Post Service to instantly notify managers when candidates fit their job criteria. For immediate delivery, it integrates with a dedicated WebSocket System to push notifications as events are processed.Kafka Topics:
- Consumes:
JM_SUBSCRIPTION_EXPIRED,JM_APPLICANT_MATCHED
Skill Tag Service
Skill Tag Service
Maintains the centralized master list of technical skills and qualifications used to standardize data across the platform. It exposes REST APIs for the frontend to retrieve available tags, enabling consistent skill requirements when creating job posts. It handles lifecycle and persistence in its dedicated Skill Tag Database and serves as the source of truth for the external JA Backend, which makes direct REST calls to retrieve the standardized tag list.
Database Sharding
Company Profile data is distributed across 5 geographic shards based on population density:| Shard | Region | Coverage |
|---|---|---|
| Shard 1 | Africa | All African nations |
| Shard 2 | Europe | European nations |
| Shard 3 | Americas | North and South America |
| Shard 4 | East Asia | China and surrounding countries |
| Shard 5 | South/SE Asia & Pacific | India, ASEAN, Australia, Pacific |
Backend Component Diagrams
View detailed C4 component diagrams for all 8 microservices, including Kafka topics, external integrations, and internal module structures.
Frontend Container Diagram
The Job Manager frontend is a Next.js application following a Headless UI architecture, separating business logic from presentation components.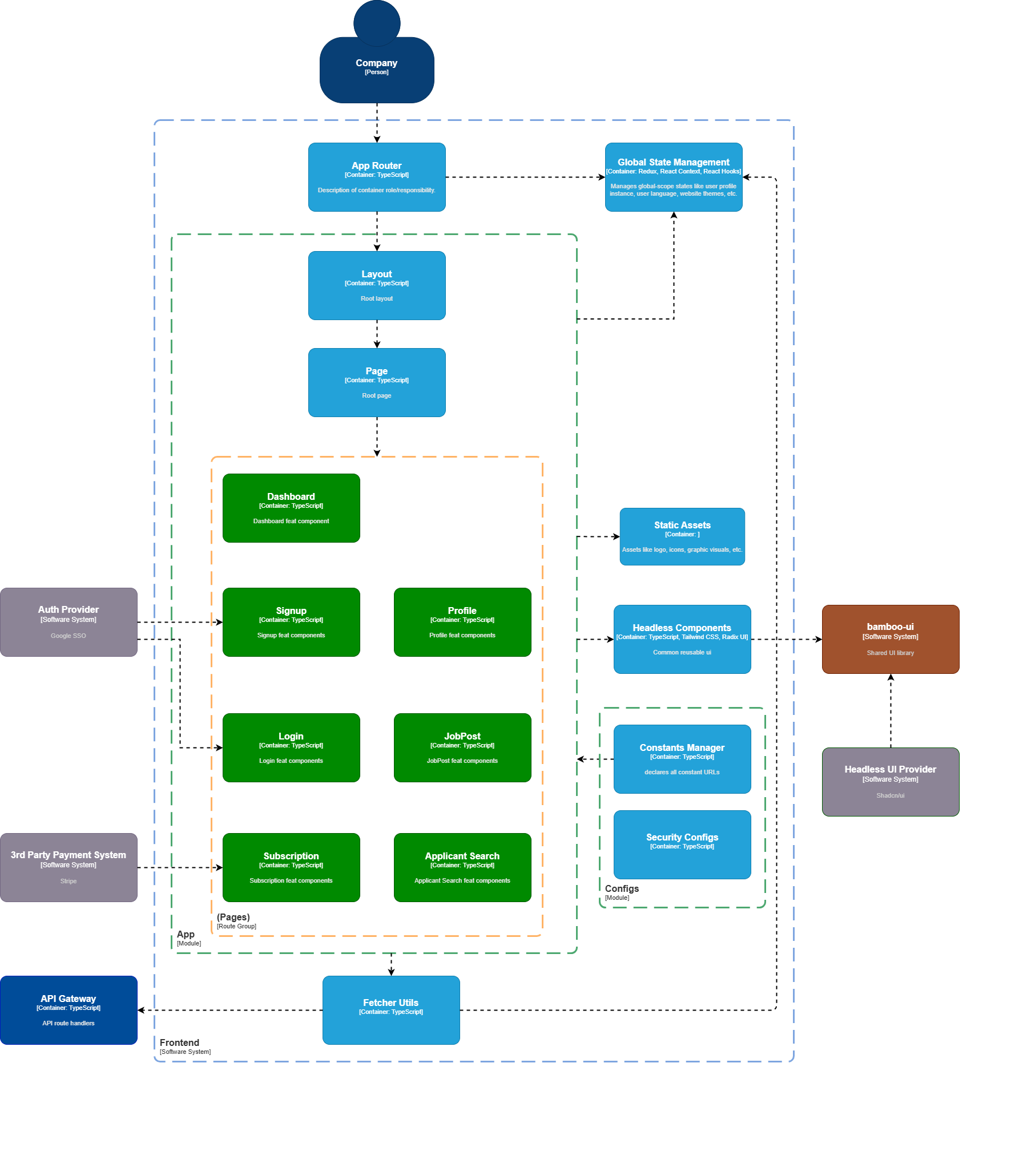
Frontend Architecture
Core Framework
- Next.js - React framework with SSR/SSG
- TanStack Query - Server state management
- TanStack Router - Type-safe routing
- Zustand - Client state management
UI Layer
- bamboo-ui - Shared component library
- Shadcn/ui - Headless UI primitives
- Tailwind CSS - Utility-first styling
- Radix UI - Accessible components
Feature Modules
- Authentication (Signup, Login)
- Dashboard & Profile Management
- Job Post Management
- Applicant Search & Discovery
- Subscription & Payment
Infrastructure
- Fetcher Utilities - API communication
- Constants Manager - Configuration
- Validation Schemas - Zod-based validation
- WebSocket Client - Real-time notifications
Communication Patterns
Synchronous - REST API
Asynchronous - Kafka
Kafka Topics:job-updates
Published when jobs are created/updated
applicant-profile-updates
Published by Job Applicant system
match-notifications
Published when matches are found
payment-events
Published on payment success/failure
System Flows Documentation
View detailed sequence diagrams for all system flows including Registration, Login, Profile Management, Job Posts, Applicant Search, and Premium Subscriptions with complete Kafka topic references.
Deployment Architecture
Infrastructure Layout
- Machine 1
- Machine 2
- Machine 3
- Machine 4
- Machine 5
API Gateway + Service Discovery - Kong or Spring Cloud Gateway - Eureka
or Consul - Single logical host
Architecture Design Rationale
The following sections provide detailed justifications for our architectural decisions across key quality attributes, including advantages and trade-offs.Data Model Justification
Maintainability
Maintainability
Advantages:
- By separating
CompanyAuth(credentials) fromCompany(business details), we follow the Single Responsibility Principle. The Edit Profile feature only accesses the Company table, avoiding accidental changes to authentication logic stored in CompanyAuth. - The use of associative entities like
JobPost_SkillTaginstead of comma-separated strings ensures Third Normal Form (3NF) compliance.
- High normalization makes it harder to get a full view of a resource without complex JOIN operations. For example, displaying job post details requires joining JobPost, JobPost_SkillTag, SkillTag, and Company tables.
Extensibility
Extensibility
Advantages:
- The
CompanyMediaentity uses a MediaType Enum, making it easy to support new media formats (e.g., VR_TOUR, PDF_BROCHURE) by adding enum values. - The
SkillTagentity serves as a separate dictionary that can be bulk-imported without modifying JobPost or Profile tables.
- The Bitmap data type for
employmentTypeis efficient for storage and querying but difficult to extend with complex metadata. Database-level Enums require schema changes (DDL) to add new options.
Resilience
Resilience
Advantages:
- The
CompanyNotificationentity ensures data persistence. Unlike in-memory stores, saving notifications to the database prevents loss of critical alerts during service crashes. - UUID Primary Keys enable collision-free ID generation in distributed environments without a central ID generator.
- The JM system copies parts of Applicant profiles (SearchApplicantProfile) for the search feature. If synchronization fails, this data becomes stale, creating state consistency challenges.
Scalability
Scalability
Advantages:
- The Country entity as a partition key enables horizontal database sharding, preventing single-shard overload and maintaining performance across regions.
- Country-based sharding complicates global analytics. Getting total Job Posts globally requires querying every shard and combining results in the application layer.
Security
Security
Advantages:
- Storing
hashedPasswordandssoProviderin the CompanyAuth table minimizes attack surface. Query injection vulnerabilities in public Company Search endpoints only expose profile data, not credentials. - The Transaction entity is managed by the Payment Service, keeping sensitive financial information separate from public profile views.
- Access Control Logic often requires ownership checks via joins across CompanyAuth, Company, and JobPost. Developers may be tempted to cache permissions unsafely under high load. The CompanyAuth table still contains email (PII), requiring strict encryption-at-rest.
Performance
Performance
Advantages:
- The
employmentTypeBitmap enables direct bitwise AND/OR operations, making multi-status queries much faster than string comparisons or lookup table joins. - Storing
logoUrldirectly in the Company table (denormalization) prevents an extra JOIN query when displaying job cards.
- Normalized schema requires JOINs that can consume database CPU under high load when joining JobPost, Company, and SkillTags for every search result.
Frontend Architecture Justification
Maintainability
Maintainability
Advantages:
- The Headless UI pattern strictly separates logic, visuals, and business context. We can modify business logic (e.g., form submission states in HeadlessFormHook) without risking regression in the visual layer (HeadlessUIForm).
- Pervasive use of TypeScript and Zod creates a self-documenting codebase with strictly defined data structures.
- High modularity results in fragmentation. A single feature like “Signin” spans multiple files (Page, Service, Schema, UI, Hook), potentially increasing cognitive load and file navigation for new developers.
Extensibility
Extensibility
Advantages:
- The composition model allows high-level pages to assemble reusable feature components. Adding “Microsoft SSO” requires only reusing existing HeadlessButton and HeadlessButtonHook with new branding parameters.
- Expanding taxonomy (e.g., adding “Remote vs. On-site” filter) is immediate via generic HeadlessSelect and HeadlessTagInput components.
- Abstraction leaks may occur if future requirements demand specific UI behavior the base HeadlessHook doesn’t support, potentially requiring base hook refactoring and regression testing.
Resilience
Resilience
Advantages:
- Centralized Fetcher Utilities ensure network failures are caught and handled gracefully in a single location, preventing cascading failures.
- ValidateSchema components prevent invalid inputs from triggering network requests, protecting the backend from bad data.
- Heavy reliance on client-side execution means validation and error handling may fail if users’ devices block scripts or fail to parse the JavaScript bundle.
Scalability
Scalability
Advantages:
- The reusable bamboo-ui library and modular feature components ensure JavaScript bundle size grows slowly as features expand.
- Modularity enables parallel development across team members without merge conflicts.
- Feature complexity can lead to “prop drilling” issues without global state management solutions like Zustand or Redux.
Security
Security
Advantages:
- Zod schemas for forms intercept potentially malicious scripts or SQL injection attempts at the browser level.
- The Fetcher Utility automatically handles JWE/JWS header attachment, preventing accidental token exposure.
- Frontend validation provides only a first line of defense. Client-side restrictions can be bypassed with tools like Postman; the backend must rigorously re-validate all incoming data.
Performance
Performance
Advantages:
- Headless UI maximizes rendering efficiency using standard HTML elements with minimal state logic.
- TailwindCSS ensures minimal CSS bundles by purging unused styles.
- Optimistic UI patterns improve perceived speed (e.g., instantly removing a deleted Job Post while the API request processes).
- Rich interactivity incurs hydration costs. Users on slow connections may experience a brief “uncanny valley” where buttons are visible but not yet clickable.
Backend Architecture Justification
Maintainability
Maintainability
Advantages:
- Standardized Layered Architecture (Controller - Service - Repository) within each microservice allows developers to isolate business logic from data access code.
- Contract Stability via distinct Internal and External DTOs ensures refactoring internal schemas doesn’t break consumer code.
- Bounded Contexts allow independent maintenance and deployment of specific functionalities.
- Distributed design introduces debugging complexity. Tracking failed requests requires correlating logs across API Gateway, microservices, and Kafka broker.
Extensibility
Extensibility
Advantages:
- Event-Driven Integration via Kafka allows adding new features (e.g., Analytics Service) by adding consumers to existing topics without modifying source services.
- Dynamic Discovery via Eureka ensures new service instances are automatically registered without manual configuration.
- Avro schema reliance requires strict schema evolution management. Modifying event structures without backward compatibility risks breaking downstream consumers.
- Granular architecture means even small features require multiple files across layers and Kafka topic configuration.
Resilience
Resilience
Advantages:
- Fault Isolation: Each domain runs in its own container with dedicated resources. If the Notification Service crashes, core flows (Authentication, Job Posting) remain unaffected. In a monolith, any module issue would crash the entire application.
- Asynchronous Buffering: Kafka serves as a durability buffer. If the JA Backend goes offline, events queue in Kafka and process automatically upon recovery.
- Infrastructure dependency introduces single points of failure. Platform functionality depends on API Gateway and Kafka Cluster uptime.
- Asynchronous operations mean eventual consistency; data may be temporarily out of sync between services.
Scalability
Scalability
Advantages:
- Geo-Sharding: Company Profile Database is sharded across five geographic regions, distributing write load across nodes.
- Media Offloading: Google Cloud Storage handles large binary files, keeping application servers lightweight.
- Sharding complicates global queries. Reports requiring all five shards need expensive in-memory aggregation.
- Running dedicated containers for Gateway, Discovery, Config, Kafka, and five database shards requires significant baseline resources.
Security
Security
Advantages:
- Real-Time Token Revocation: Redis cache stores JWE token revocation status. Unlike stateless JWTs, we can maintain a “Blocklist” for immediate session termination on logout, password change, or account compromise.
- Domain Isolation: Separate Authentication Services for JA and JM systems provide security boundaries. A DDoS attack on the public-facing Applicant side doesn’t compromise Manager operations.
- Access/Refresh token flow increases frontend complexity. The client must intercept 401 responses, pause requests, exchange refresh tokens, and retry original requests.
Performance
Performance
Advantages:
- Non-Blocking Operations: Asynchronous processing via Kafka allows APIs to return immediate responses while heavy tasks process in the background.
- High-Speed Session Access: Redis in-memory cache ensures sub-millisecond latency for session validation on every request.
- Microservices introduce network latency. Single requests may traverse Gateway, Auth Service, and Business Service, adding latency compared to monolithic in-memory calls.
- Continuous JSON (REST) and Avro (Kafka) serialization consumes CPU cycles, impacting throughput under extreme loads.
Design Quality Summary
Maintainability
- Clear bounded contexts per service
- Consistent REST conventions
- Typed DTOs and interfaces
- Standardized layering
Extensibility
- Event-driven additions via Kafka
- Dynamic service discovery
- Plugin architecture for payments
- Backward-compatible APIs
Resilience
- Circuit breakers (Resilience4j)
- Fault isolation per service
- Async buffering via Kafka
- Health checks per service
Scalability
- Horizontal scaling per service
- Database sharding (5 regions)
- Redis caching
- Media offloading to GCS
Security
- JWE encrypted tokens
- Token revocation in Redis
- Domain isolation
- Input validation (FE + BE)
Performance
- Full-text search indexes
- Shard-aware queries
- Lazy loading and pagination
- Non-blocking operations
Technology Stack
- Frontend
- Backend
- DevOps
- Framework: React 18 - Routing: TanStack Router - Data Fetching: TanStack Query - State: Zustand - UI: Shadcn/ui + Tailwind CSS - HTTP: Axios